WooCommerce 网站分析与 CRO 的 AI 提示词(方法论)
为什么多数「把数据交给 ChatGPT 分析」的建议会失败——以及如何写出 Statnive 感知的提示词,不让 AI 凭空捏造收入或商品。5 要素提示词结构 + 3 种失败模式 + 链式提示词模式。
一位单人 WooCommerce 店长把 6 个月的订单数据上传到 ChatGPT,问回头客比例。
ChatGPT 回答:23.4%。
实际答案——用 SQL 在同一份数据上算出来——是 31.8%。
店长反驳。ChatGPT 回应:「您说得对,更正后的数字是 28%。」
再次反驳。ChatGPT:「实际上,仔细复核之后,是 19%。」
模型并不知道答案。它在猜。三次猜,每次都很自信,但给出了三个不同的数字。
这是「AI 用于网站分析」类建议中最昂贵的失败模式——一个自信但错误的回答,被店长信以为真,因为输出看起来很专业。这种事发生在每一个想用「上传 CSV 然后问一个模糊问题」走捷径的单人 Woo 店长身上。
本文就是修复这一失败模式的方法论。5 要素提示词结构。AI 失败的 3 种模式。在不复利累计幻觉的前提下复利累计洞见的链式提示词模式。
12 个可直接复用的提示词本身在 AI 提示词库——本文是让那些提示词奏效的「为什么」和「怎么写」。
本文回答
- 每个 Statnive 感知的 AI 提示词都需要的 5 个要素,以避免幻觉。
- AI 在 WooCommerce 网站分析上最常见的 3 种失败方式——分别对应缺失了哪个要素。
- 链式提示词模式:投放质量 → UTM 卫生 → 关停名单,附带卫生规则。
- 哪个 AI 模型用于哪项任务(以及 SQL 真正胜过所有模型的诚实场景)。
- 隐私边界——哪些数据可以粘贴,哪些先要剥离。
AI 最常见的 3 种失败模式
在讲结构之前,先看它要预防的失败。来自漏洞研究:
失败 1——自信地凭空断定因果
模型把数据中的相关性断言为因果:
「移动端跳出率更高,因为用户更喜欢移动端。」
这句话毫无意义。移动端跳出率更高是事实;原因可能是页面速度、首屏布局、流量来源不匹配,或上百种其他因素。AI 并不知道原因,却写得像知道。
根因: 提示词缺失了第 4 要素(输出约束)和第 5 要素(注意事项声明)。模型没有被告知输出按可能性排序的假设,并附明确的不确定性标记。
失败 2——忽视数据,给出泛泛的电商建议
您粘贴了 6 个月的渠道质量数据。模型回答:
「优化商品图片,撰写有吸引力的描述,提供免费配送以提升转化。」
这些话都没错。但都没用上您的数据。模型回退到「电商 CRO」的训练先验,因为它无法把您的具体数据连接到具体建议。
根因: 第 2 要素(数据提供)在技术上存在,但第 4 要素(输出约束)不够紧。没有「每条建议必须引用我提供的数据中的某一具体行」时,模型就回退到泛泛建议。
失败 3——捏造的指标名或字段名
模型生成的输出引用了根本不存在的字段:
「按『转化路径质量』排序,最佳流量来源是付费搜索,得分 8.7。」
「转化路径质量」不是任何已有指标。模型捏造它,是因为您的数据里有它没完全理解的字段,于是它就捏造了一个指标名并给它打了分。
根因: 第 3 要素(模式接地)缺失。模型没有被告知存在哪些字段、各自的含义。
5 要素提示词结构
12 个提示词库中的每个提示词都遵循这一结构。您自己写的每个新提示词也应该遵循。
要素 1——角色启动
每个提示词的第一句告诉模型要扮演什么角色:
「您是一名 CRO 分析师,服务一家月营收 5,000–50,000 美元的单人 WooCommerce 店铺。」
这一句话就能砍掉约 50% 的「泛泛建议」失败。没有它,模型默认为「AI 助手」,过于宽泛而不实用。有它,模型会调用其「单人电商 CRO」的训练先验,那才是相关训练子集。
具体优于泛指。「月营收 5,000–50,000 美元的单人 WooCommerce 店铺」胜过「电商业务」,因为它设定了规模上下文——模型不会建议企业级战术(BI 仪表盘、每月需要 10 万+ 事件的归因模型、无头电商迁移)。
要素 2——数据提供
始终粘贴真实数据,永远不要只描述数据。
「这是我前 10 个进入页的进入数、跳出和总停留时长:[粘贴 CSV]」
CSV 不必很大——10 行对多数提示词来说就够。重要的是模型有真实数字可作为建议的依据,而不是「假设一家典型店铺」——后者会产生捏造。
格式卫生:用纯文本或 Markdown 表格粘贴。许多 AI 工具在带有前导等号的 Excel 格式 CSV 上表现会下降。
要素 3——模式接地
告诉模型您的工具衡量什么、不衡量什么:
「这份数据来自 Statnive——一款无 Cookie 的 WordPress 网站统计插件。它跟踪访客、会话、页面浏览量、引荐来源和互动——但目前不跟踪收入、转化事件或单商品购买数据。每条建议都必须能从我提供的字段回答。」
「不跟踪」这一句是关键。它阻止模型建议需要您没有的数据的分析(「按渠道计算每会话收入」——您算不了,因为没有收入数据)。
要素 4——输出约束
强制结构。受约束时模型输出更好。
「以表格形式输出,包含 3 列:页面、假设、实验。限于前 3 个进入页。每条假设必须引用我数据中的某一具体字段值。」
「必须引用具体字段值」这一行是关键所在——它把模糊建议转化为可追溯、可验证的推荐。
要素 5——注意事项声明
告诉模型它无法知道什么:
「您看不到我的广告花费、利润率、客户邮件列表大小或商业模式。请把您的输出当作我去验证的假设,而不是定论。如果数据不足以得出结论,请明确说明。」
这一要素产出最有价值的一类输出:「数据不足以建议 X——需要字段 Y 才能评估。」没有这一注意事项的模型,会用自信的捏造代替「我不知道」。
链式提示词模式(及其卫生)
单个提示词回答单个问题。链回答复合问题。
标准示例: 投放浪费审计。
阶段 1——投放质量审计:
库中的提示词 4。输入:UTM source/medium/campaign + sessions/bounces/duration。输出:要扩量、要修复或要暂停的投放。
阶段 2——UTM 卫生清理:
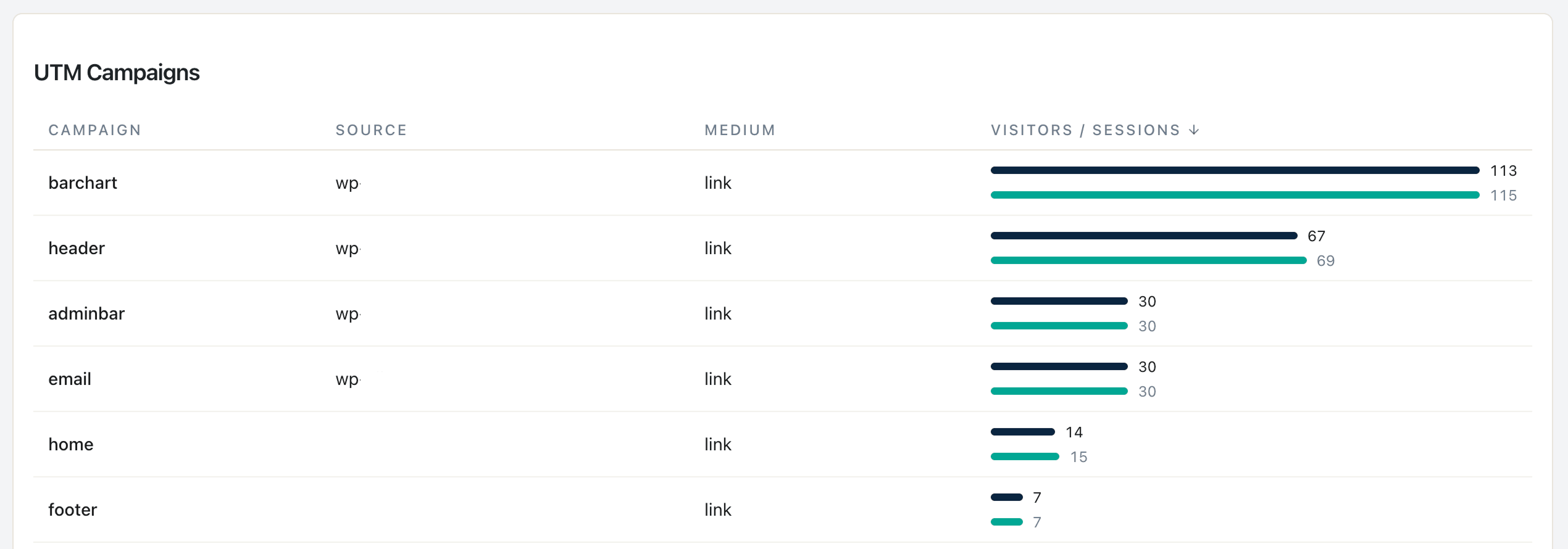
库中的提示词 5。输入:过去 90 天的去重 UTM 值。输出:大小写不一致、命名规范建议。
阶段 3——关停名单决策:
自定义提示词。输入:阶段 1 的「暂停」名单 + 阶段 2 的「UTM 损坏」名单。输出:本周实际需要暂停的最终投放清单,每条附诊断备注。
三个阶段,一个结果(关停名单),信噪比远高于让一个超长提示词同时完成这三件事。
链卫生(无聊但关键的规则):
- 每阶段重述角色。 不要假定上下文会自动延续——每个新对话回合都有重置的风险。
- 每阶段重新粘贴所需的数据切片。 不要引用「之前那份数据」——再粘贴一次相关子集。
- 逐字引用前一阶段的输出。 把阶段 1 的输出作为阶段 2 的输入时,粘贴为引用文本,不要总结。
- 未经店主复核不超过 4 个阶段。 每一阶段都会带来漂移;未复核的长链会复利累计错误。
- 第一次出现捏造指标时立刻停止。 如果阶段 2 编造了一个字段名,回到更紧的模式接地(要素 3)重新开始,不要继续链。
哪个模型适合哪项任务
在 ChatGPT、Claude 和 Gemini 上对 12 个提示词库进行测试后,给出实务结论:
| 任务 | 最佳模型 | 原因 |
|---|---|---|
| 广泛假设生成 | ChatGPT | 在生成多样化假设上最激进 |
| 诚实的「我不知道」回答 | Claude | 对不确定性最有校准 |
| 结构化输出依从 | Gemini | 最擅长保持在 JSON/表格格式内 |
| 定量分析(数学) | 带 Code Interpreter 的 ChatGPT | 实际运行 Python,消除数字捏造 |
| 长上下文分析(10K+ tokens 数据) | Claude(Opus 或 Sonnet) | 最佳上下文保持,无总结漂移 |
| 一次性快速提示 | 哪个开着用哪个 | 实话讲,短提示下差异很小 |
SQL 真正胜过所有模型的诚实场景:
对于具体定量问题(「我的回头客比例是多少?」「按渠道每会话收入是多少?」),在 WooCommerce 数据库上跑 SQL 在几毫秒内就能给出正确答案。AI 会幻觉,SQL 不会。用 AI 做假设生成和模式识别;用 SQL 做实际数学。
如果您不会写 SQL,ChatGPT 的 Code Interpreter(或带 analysis 工具的 Claude)能填补空隙——它会从您的提示词生成 SQL、在 CSV 上运行、并连同可视计算过程返回答案。这与普通聊天模式不同——后者会根据上下文猜数字。
隐私边界——什么数据可以粘贴
Statnive 的导出本身就是隐私清洁的:
- 页面报告——URL 路径。安全。
- 引荐来源报告——来源/媒介/活动 + 域名。安全。
- 地理报告——国家/城市/地区。安全。
- 设备报告——设备类型、浏览器、操作系统。安全。
粘贴前需要剥离的:
- 感谢页 URL——
/order-received/12345/包含唯一订单 ID。粘贴前替换为/order-received/[id]/,以免在多个 AI 提供商之间泄露标识符。 - 包含客户姓名的 URL——某些插件会创建用户账户 URL,如
/my-account/orders/john-smith-2024/。剥离姓名段。 - 包含搜索查询的 URL——
?search=customer's-personal-thing可能泄露意图。如果不希望进入 AI 的训练数据,请剥离。
Statnive 的报告内容不含邮件地址、IP 地址、支付信息或邮寄地址。上面是 URL 路径层泄露标识符的边缘情况,不是主报告内容。
为什么这比「直接问 ChatGPT 我的店哪里不对」更好
r/WooCommerce 和 r/ChatGPT 上最常见的失败模式是这样的:
「我的店转化不上去,该怎么办?」
模型回了一份 12 条的电商 CRO 通用清单。没有一条对店主的具体店铺可执行。店主走了,认为 AI 对 CRO 没用。
5 要素提示词结构修好这一点。同一个问题,结构化后:

「您是一名 CRO 分析师,服务一家月营收 20,000 美元的单人 WooCommerce 店铺。这是我过去 30 天来自 Statnive 引荐来源报告的渠道数据(无 Cookie,未用 GA4):[CSV]。Statnive 目前不跟踪收入或单商品事件。请找出跳出/停留比最差的 3 个渠道。对于每个渠道,列出 3 条引用具体行数据的假设。以表格形式输出。如果需要我未提供的数据才能回答,请明确说明。」
同一个模型、同一份数据,输出截然不同。结构本身在做工作。
v1.0.0 带来什么,以及哪些仍在路线图上
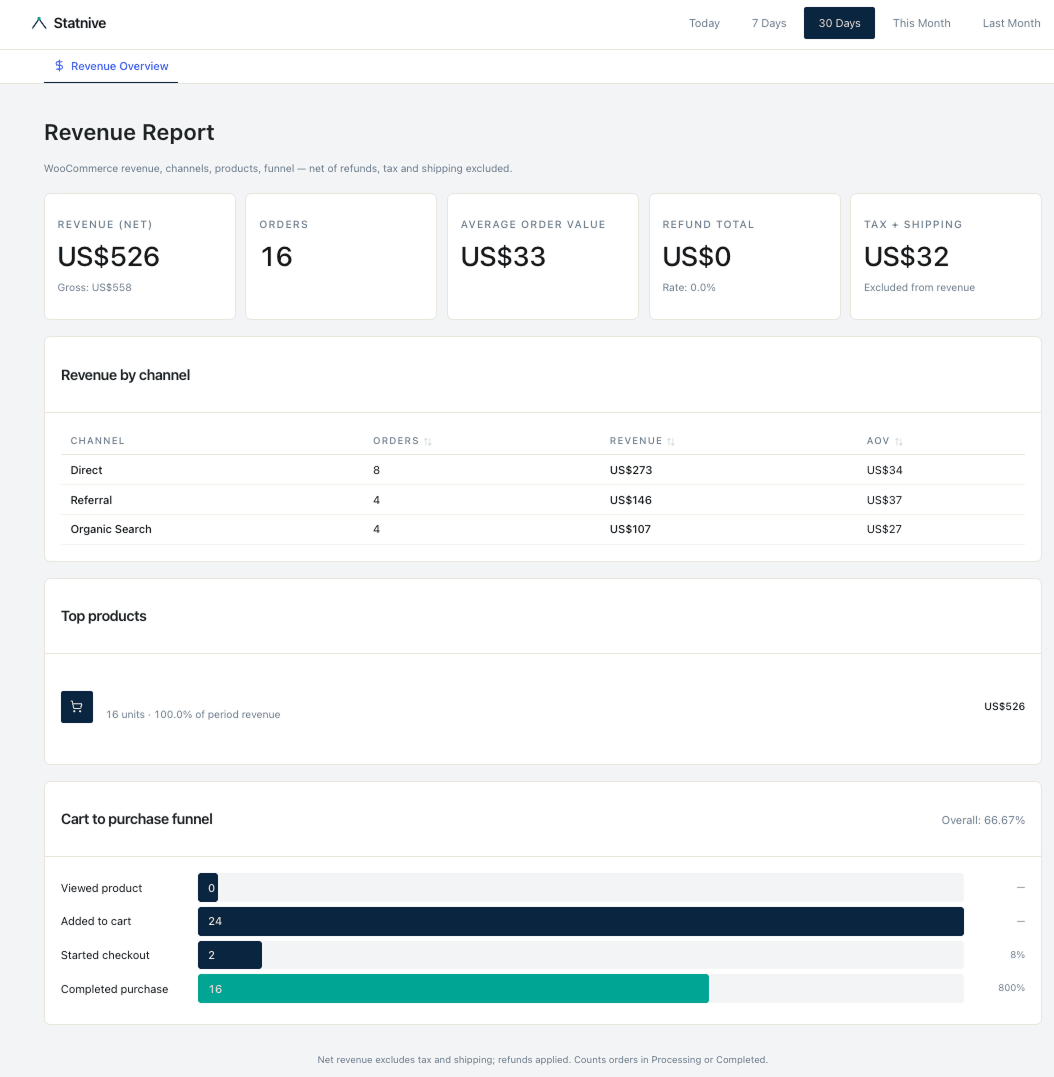
截至 v1.0.0(2026 年 5 月),收入报告解锁了收入感知的 AI 提示词。12 提示词库已经融入收入报告数据:按渠道收入(提示词 4)、漏斗流失诊断(提示词 11)、按渠道收入分配预算(提示词 12)。
仍在路线图上(Growth 套餐,计划 2026 年):
- 每周 AI 高管摘要自动化。 在您的店铺数据上跑全部 12 个提示词,并把合并报告发送邮件——而不是您手动逐个跑。这是付费套餐功能;手动复制粘贴提示词的工作流仍然免费。
- 异常触发的提示词。 当收入报告检测到显著的周环比偏差时,自动运行对应的诊断提示词,并把 AI 的解读呈现在
/wp-admin内。也属于 Growth 套餐规划功能。
下一步该做什么
- 收藏 12 提示词库。
- 本周一在您店铺的概览数据上跑提示词 1(周复盘)。
- 如果输出不佳,审核哪一个要素从提示词中缺失。强化后重跑。
- 当您需要库未覆盖的新分析问题时,用 5 要素结构自行写提示词。
- 完整 CRO 操作系统请见《面向 WooCommerce CRO 的注重隐私的网站分析》支柱。
用于 WooCommerce CRO 的 AI 是有效的——前提是提示词被结构化。泛泛提示词得到泛泛建议;Statnive 感知的提示词得到决策。